昨天介紹評估推論(或者測試)結果的方法,今天要來介紹混淆矩陣(Confusion Matrix)。混淆矩陣也是在分類問題上常被使用的評估方法,顯示預測結果和真實值的比較,再利用一些工具將混淆矩陣繪製出來,更能看出推論結果,幫助模型的改善。
一個二分類的混淆矩陣如下:
| 預測為真 | 預測為假 | |
|---|---|---|
| 實際為真 | TP | FN |
| 實際為假 | FP | TN |
對角線就是預測正確的數量。由混淆矩陣可以更好分析預測結果,對於結果的判讀不會由單一準確度結果做評斷。接下來介紹兩種方法,來繪製混淆矩陣,建議延續昨天的程式碼使用。
Seaborn 為基於 Matplotlib 的 Python 視覺化工具庫,更專注於繪製統計圖表的功能。
import seaborn as sns
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# 定義混淆矩陣
cm = confusion_matrix(y_true, y_pred)
# 使用 seaborn 繪製
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['black', 'grizzly', 'panda', 'polar', 'teddy'],
yticklabels=['black', 'grizzly', 'panda', 'polar', 'teddy'])
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
使用 sklearn.metrics 中的 confusion_matrix 計算混淆矩陣: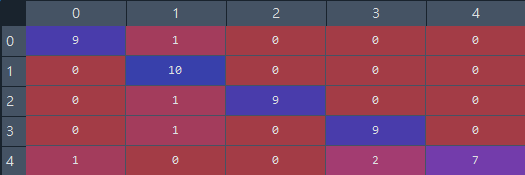
(使用 Spyder 查看 cm 變數的結果)
使用 seaborn.heatmap() 繪製熱圖(Heat Map),annot 設定為 True 會顯示對應數值,fmt 設定 'd' 表示以整數顯示,cmap 用來設定顏色系統,xticklabels 和 yticklabels 分別為 x 軸和 y 軸的標籤。
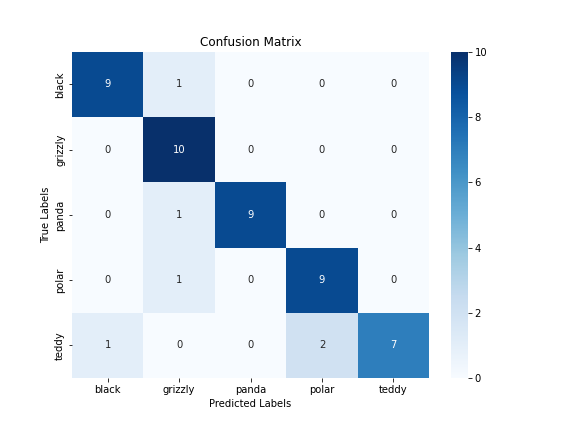
來自 scikit-learn 的方法,功能是繪製混淆矩陣圖表:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 定義混淆矩陣
cm = confusion_matrix(y_true, y_pred)
# 使用 ConfusionMatrixDisplay 繪製
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=['black', 'grizzly', 'panda', 'polar', 'teddy'])
disp.plot(cmap='Blues')
使用 ConfusionMatrixDisplay() 並設定混淆矩陣變數與標籤,再使用 plot() 設定顏色系統,就可以繪製混淆矩陣圖表了。
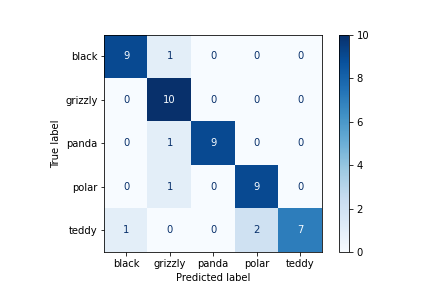
這樣推論結果是不是更一目了然了呢?顏色愈深表示數值愈大,也更方便分析推論結果。
模型的部分就在此告一段落,明天開始要介紹部署的方法了~


 iThome鐵人賽
iThome鐵人賽